
对话型AI的token消耗与上下文的累积长度直接相关,这也是导致响应变慢和对话次数消耗更快的重要原因之一。
写在前面,本站长林兄提供长期正规、稳定的chatgpt代订阅服务。请认准www.gpt516.com,查看更多产品介绍。或者加站长微信:3056978,10 分钟办好。

首先我们要了解Token消耗机制
- 上下文累积:
每次对话时,AI不仅需要处理当前输入,还需要携带之前的上下文内容(包括用户提问和AI回答)。这意味着对话轮数越多,携带的上下文越长,token消耗也会成倍增加。 - 计算示例:
- 第1次对话:输入13个token,AI回答1000个token,总消耗为 13 + 1000 = 1013。
- 第2次对话:输入3个token,但需要携带之前的1013个token,加上AI的回答6个token,总消耗为 1013 + 3 + 6 = 1022。
- 第3次对话:输入2个token,同样携带前两轮的上下文(1013 + 1022),加上AI回答6个token,总消耗为 1013 + 1022 + 2 + 6 = 2043。
结论:随着对话轮数增加,每次交互时需要处理的上下文长度变长,导致token消耗呈指数级增长。
响应变慢和次数消耗加快的原因
- 模型处理复杂性:
模型在每次生成响应时,需要重新读取并理解完整的上下文,这会增加计算负担,从而导致响应变慢。 - 对话次数限制:
一些平台(如ChatGPT)可能会根据用户套餐或服务级别,对每日或每月的token使用量设定上限。由于上下文累积导致每次交互消耗更多token,因此用户会更快达到使用上限。
优化建议
- 减少上下文累积:
- 如果当前对话与之前内容无关,可以开启一个新的对话窗口,从而清空上下文,避免不必要的token累积。
- 对于较长的对话,可以定期总结关键点并用简短语言重启新对话。
- 简化输入和输出:
- 提问时尽量精简,不发送过长或复杂的问题。
- 避免生成大段文字(如1000字以上),以减少AI回答时的token消耗。
- 选择适当服务等级:
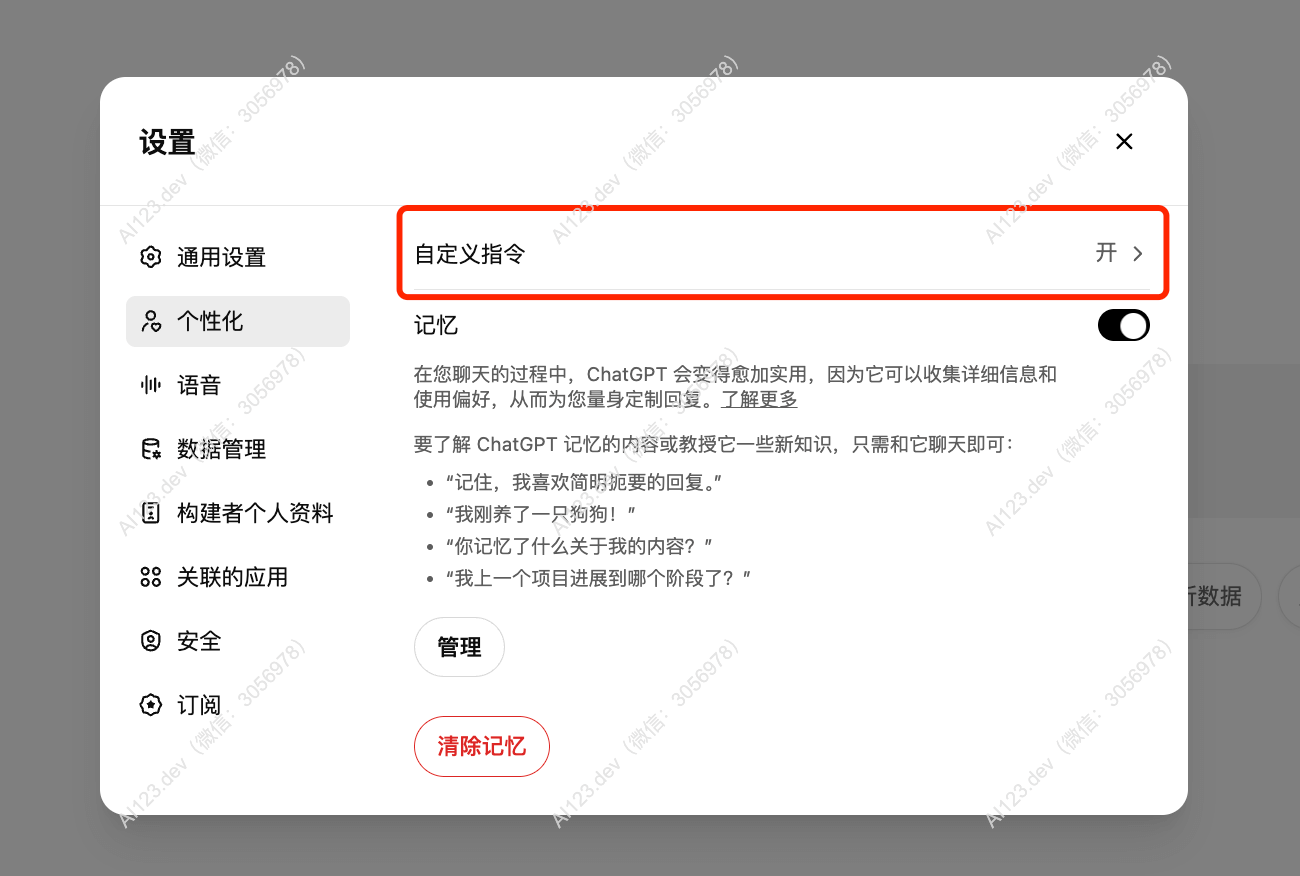
如果频繁使用AI并需要处理大量上下文,可以考虑升级到支持更多token限制或性能更高的服务版本。 - 可以从设置-个性化 这里可以输入你的一些常用的偏好
通过这些方法,可以有效降低响应延迟,同时延长可用对话次数。
站长可以提供长期正规、稳定的chatgpt代订阅服务,加站长微信:3056978,保证你能用上chatgpt!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
AI行业发展迅速,内容及时性请保持自己的判断,正如 ChatGPT 所述其可能会发错,注意核实信息